Maamerkkien tunnustamisen haaste – Kehitys ja kokemukset

Tässä viestissä haluan jakaa kokemukseni Kagglen Landmark Recognition Challenge -tapahtumassa. Tässä artikkelissa opit kehittämään koneoppimismallin maamerkkien tunnistamiseksi kuvissa 15 k: n luokista. Kaggle-kilpailut, kuten Landmark Recognition, tulevaisuudessa. Haluan tehdä tiivistelmän kokemuksistani tämän artikkelin lopussa. Löydät koodin tästä arkistosta.
Maamerkkien tunnustamisen haaste
Toistaiseksi kuvan luokitteluhaasteet (esimerkiksi ImageNetin suuren mittakaavan visuaalisen tunnistuksen haaste) pidettiin yksinkertaisena pienen luokan lukumäärän ja paljon koulutusesimerkkejä luokkaa kohden. Landmark Recognition asettaa uudet standardit kuvan luokittelussa, ja sillä on tähän mennessä suurin maailmanlaajuinen tietojoukko. Lisäksi yksi tai jopa muutama harjoituskuva. Aluksi nämä äänet ovat vaikeampia kuin vanhemmat haasteet. Mutta on olemassa kaksi muuta käärmettä, jotka vievät Landmark Recognition Challengen seuraavalle tasolle:
- On testikuvia kanssa ei maamerkkiä.
- On testikuvia kanssa useampi kuin yksi maamerkki.
Lisäksi olisi parempi ennustaa maamerkkikuva, jos ennustepiste on liian matala. Kirjoitin luokitukseni lähettämistä csv-tiedostoon. Tämän tiedoston tulisi sisältää otsikko ja sen muodon tulisi olla seuraava:
Perustuu globaaliin keskimääräiseen tarkkuuteen (GAP), jota kutsutaan mikrokeskimääräiseksi tarkkuudeksi (microAP). Lopullinen sijoitus (Kagglerin kielellä: "Tulostaulu") luodaan GAP-arvon perusteella. Jos haluat tietää enemmän GAP-tiedoista, napsauta tätä.
Tietojen esikäsittely
Tämän kilpailun osalta latasin seuraavat kaksi tietojoukkoa:
- train.csv: 1.225.029 csv-rivit URL-osoitteilla, joiden avulla koulutetaan kuvia, jotka on merkitty niihin liittyvällä maamerkillä
- test.csv: sisältää 117 703 csv-riviä URL-osoitteilla kuvien testaamiseksi
Kuten aiemmin sanottiin, testikuvissa ei voi olla maamerkkiä, yhtä maamerkkiä tai useampaa kuin yhtä maamerkkiä. Harjoittelukuvissa kukin kuvaa yhtä maamerkkiä. Jokainen kuva sisältää yksilöllisen tunnuksen, URL-osoitteen ja merkityn maamerkin tunnuksen.
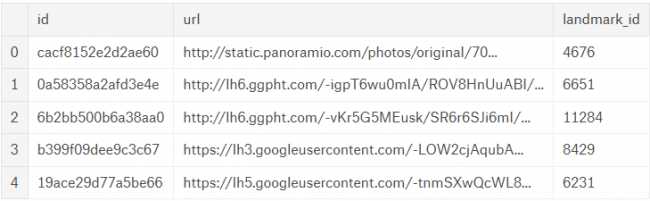
Juna-aineisto, jossa on tunnus, URL ja maamerkki_id
Testitiedot sisältävät kukin kuvan yksilöllisen tunnuksen ja kuvan URL-osoitteen.
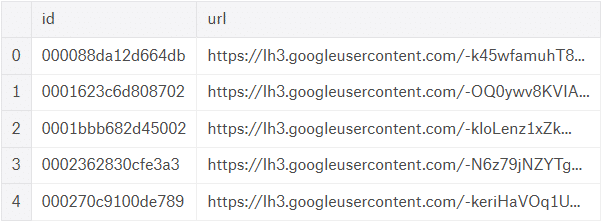
Testaa tietojoukko tunnuksella ja URL-osoitteella
Kuten huomaat, minun on ladattava kuvat ensin, ennen kuin voin käyttää niitä. Ensimmäisessä kokeiluversiossa latasin kuvat täydellä resoluutiolla (yli 350 Gt dataa). Joten päätin muuttaa heidän kokoaan. Sen jälkeen varastoin ne 128 x 128 pikselin tarkkuudella, mikä pienensi kokoa 15 Gt: ksi.
Juna- ja testikuvat ovat saatavilla samassa koossa nyt. Meillä on nyt testitietojen esikäsittelyvaihe. Mutta emme tiedä jokaisen junassa olevan kuvan merkintää. Siksi olen luonut komentosarjan, joka valmistautuu jokaiselle maamerkkiluokalle ja määrää niihin liittyvät kuvat näihin hakemistoihin. Nyt meillä on 15 000 kansiota, yksi kutakin tarraa kohti.
Mallinnus Keran kanssa ja siirto-oppiminen
Maamerkkintunnistusmallissani päätin luokitella kuvat käyttämällä Convolutional Neural Network -verkkoa (tässä tapauksessa VGG16), joka on esikäsitelty Google ImageNet -aineistossa. Keras-kirjasto sisältää erityyppisiä CNN-arkkitehtuureja, kuten käytetty VGG16. Kaksi muuta tyyppiä olisi esimerkiksi ResNet tai Inception. 1000 erityyppistä arkipäivää, kuten koira-, kissi-, erityyppisiä taloustavaroita, ajoneuvotyyppejä ja niin edelleen. ImageNet-tietojoukko sisältää kaikki nämä päivittäiset objektit. Maamerkin luokittelemiseksi käytämme siirto-oppimisstrategiaa, kuten uuttamista ja hienosäätöä, ja käytämme sitä ennakkoharjoitteluun ImageNet-tietojoukossa. Koulutuksen aikana jäädytettiin 15 ensimmäistä CNN-kerrosta, jotta verkko voi oppia ImageNet-tietojoukon kuvien ulkopuolella olevista kuvista.
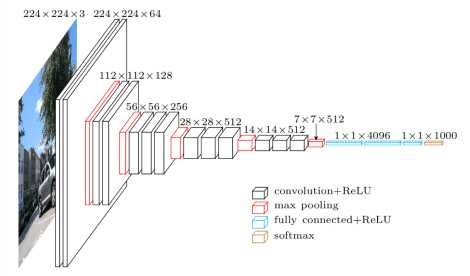
VGG16-arkkitehtuuri (Lähde: toronto.edu)
VGG16: n verkkoarkkitehtuuri on Simonyanin ja Zissermanin lehdessä 2014 (paperi).
’16’ tarkoittaa, että tähän CNN: ään on kytketty 16 kerrosta. Muuten, siellä on 19 kerrosta VGG. Sen nimi on tietenkin VGG19. Tämän mallin oletussisääntulokoko on 224 x 224. Olen kuitenkin vaihtanut resoluution 128 x 128 pikseliin paremman suorituskyvyn saavuttamiseksi.
Pullonkaulaominaisuudet
Nyt siirrytään koodiin ja katsotaan, mitkä vaiheet. Pullonkaulaominaisuudet (ts. Viimeiset aktivointikartat ennen täysin kytkettyjä kerroksia alkuperäisessä mallissa). Sen jälkeen koulun pienen täysin kytketyn verkon pullonkaulaominaisuuksilla, joten saamme luokat lähtökohtana ongelmaamme. Seuraavat VGG16: n pullonkaulaominaisuudet. Lisäksi käytän ImageDataGenerator-sovellusta kuvien muuttamiseen (koko koodi: täällä)
Harjoittele huippumallia
Kun pullonkaulaominaisuudet on tallennettu, olen nyt valmis kouluttamaan huippumalliamme. Määrittelen sille funktion, nimeltään ‘train_top_model ()’. Luon pienen täysin kytketyn verkon käyttämällä pullonkaulaominaisuuksia tulona. CNN, koska se tuhoaisi oppitut painot konvoluutiopohjassa. Tämän seurauksena haluamme vain pystyä aloittamaan koulutetun ylimmän tason luokittelijan hienosäätön.
Hienosäätöä
Tätä mallia ei vielä suoriteta, koska painot ovat edelleen ImageNetin painot – lopuksi meidän on hienosäädettävä sitä. Korkeimman tason luokittelijan ohella hienosäädä kaksi viimeistä konvoluutio-osaa ja jäädyttää 15 ensimmäistä kerrosta. Ensin on tehtävä vanha paino ja rakennettava VGG16: n konvoluutiopohja. 15. Käytämme myös suurennusta koulutuskuviin (yksityiskohtaiset tiedot Hauken blogikirjoituksessa: täällä). ‘Fit_generaattori’ auttaa syöttämään tietoja RAM: iin erissä. Ilman sitä haluat saada muistin loppumisvirheen.
koulutus
Tämä osa GPU: n käytöstä tässä yhteydessä. CNN: n kouluttaminen saa aikaan paljon aikaa GPU: lla tai jopa usealla GPU: lla. Joten tämän Landmark Recognition Challenge -tapahtuman vuoksi päätin mennä AWS: n EC2-instanssiin, jossa on jo integroitu yksi Tesla K80 GPU. Lopussa sain validointitarkkuuden lähes 80 prosenttia ja tappion noin 0,9, mikä on suuri menestys. Vaikka käytät GPU: ta, koulutus kestää useita päiviä. Ei ole mitään uutta, että VGG16 on syvänsä vuoksi erittäin haastava. Kun tämä yhdistetään paljon tietoa harjoituksen keston pidentyessä mittaamattomasti. Prosessori olisi työläs työ &# 128512;
CNN – terminaalinäkymän koulutus
ennustus
Nyt olemme valmiita siirtämään testikuvassamme verkon kautta. Minulla on maamerkkiluokka 1-15 000 ja siihen liittyvä ennustepiste tälle luokitukselle. Olen jo koonnut lähetystiedoston, koska olen jo maininnut otsikon ‘The Landmark Recognition Challenge’.
Mikä maamerkki?
On tärkeää huomata, että tätä vaihetta ei huomioida. Ensinnäkin ennustan luokan etiketin, joka olisi oikea ratkaisu. Erottelu, jos on edes maamerkki tai ei, haluan kohdata seuraavassa ennustevaiheessa. Seuraavassa näen kuitenkin koodin maamerkin etiketin ennustamiseen:
Maamerkin ennustamiseksi meidän on kuljettava saman putkilinjan läpi kuin ennen. Ennustan konvoluutiohermoverkon ennusteita. Myöhemmin purkan ennusteet ja kartan. Ja muista puhdistaa Keras-istunto jokaisen ajon jälkeen!
Onko ennuste oikea?
Kuinka päätät ennakoidun maamerkin puolesta tai sitä vastaan? Vastauksen nimi on DELF (DEep Local Features). Kuten nimestä voi päätellä, se on tapa poimia paikallisia piirteitä kuvista ja vertailla niitä. Meidän tapauksessamme DELF auttaa sovittamaan kaksi kuvaa, jotka sisältävät saman maamerkin, ja saamaan paikallisen kuvan vastaavuuden. Joten se sopii erinomaisesti maamerkin tunnustamiseen. DELF kehitettiin ja otettiin käyttöön tässä julkaisussa.
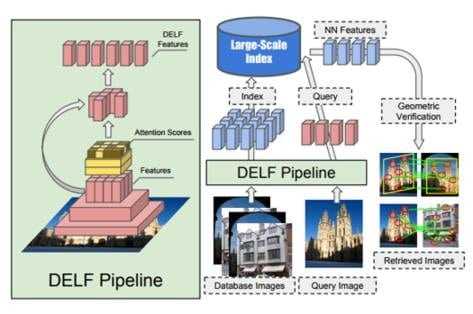
DELF-arkkitehtuuri (Lähde: DELF-paperi)
Arkkitehtuuri sisältää mekanismin, joka on koulutettu valitsemaan eniten pisteitä saaneet ominaisuudet (keltainen). DELF-putkilinjan oikealla puolella käytetään hakukentän ja joidenkin tietokantakuvien vastaavuuksien löytämistä. Hakemisto tukee kyselyä hakemalla lähimmän naapurin (NN) ominaisuudet. Lisäksi kuvan vastaavuudet perustuvat geometrisesti varmennettuihin vastaavuuksiin.
Esimerkiksi alla oleva kuva kuvaa visualisoitujen ominaisuuksien vastaavuuksia kahden kuvan välillä. Erityisen maamerkin tulisi olla NovaTec-pääkonttorimme Leinfelden-Echterdingenissä.
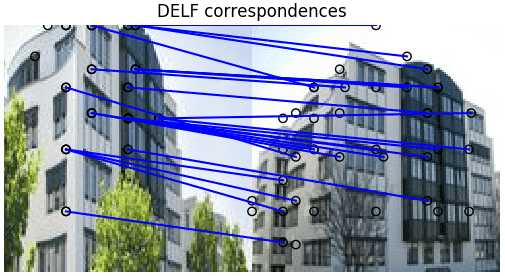
DELF-ottelut – pääkonttori NocaTec
DELF: n toteuttaminen
Ennustetun maamerkin tunnistaminen testikuvassa vie kolme vaihetta. Löydät ne arkistostani.
- Puraominaisuudet: DELF-uutto muodostaa kuvalistan
- Etsi ottelut: Ominaisuuksien vertailu tulosten saamiseksi
- Päätä tulos: Päätä, koska useista vastaavuuksista (sisennyksistä) maamerkki on totta
Kun olet luonut DELF-ominaisuudet, meidän on tehtävä vain löytää vastaavuudet näiden ominaisuuksien välillä. Kuten mainittiin, teemme tämän geometrisella varmennuksella Ransacissa. Palautettujen ‘sisääntulojen’ avulla voin mitata DELF-vastaavuuksia. Se tarkoittaa, että arvo, joka on suurempi kuin 35, sisältää ennustetun maamerkin.
Kaikkia kootaessa saadaan putkisto alla esitetyllä tavalla.
Täysi maamerkkien tunnistusputki
Aloitamme luokittelemalla testikuva yhdeksi maamerkkiluokkaksi. Tarkastamme annetun luokan DELF-ominaisuuksilla purkamalla kuvat luokitelluista maamerkkikansiosta. Jos suoritettiin 20 vertailua tai sisäpuolen (35) kynnysarvo ylitettiin, tulos palautetaan. Tulos voidaan luokitella maamerkiksi tai ei maamerkkiä.
Oppitunnit
Maamerkkiputken kehittämisen aikana ja osallistumalla Kaggle Landmark Recognition Challenge -yritykseen oppin muutamia asioita.
Ensimmäinen kohta koskee laitteistoarkkitehtuurini saatavuutta. On tärkeää, että käytettävissä on riittävästi muistia ja tehokas prosessori. Sinulla on paljon tietoa. Minun tapauksessani minulla oli vain 50 Gt: n muistitilaa virtuaalikoneessani, joten päätin minimoida kuvien resoluution. Mutta korkeammalla resoluutiolla maamerkkien tunnistin voisi toimia paremmin. Yksi harjoitusvaihe kestää noin kolme päivää yhdellä GPU: lla. Jos sinulla on enemmän GPU: ita, voit suorittaa sovelluksen usean prosessoinnin näissä GPU: issa. Harjoitteluprosessi haluaa olla nopeampi ja voit iteroida useammin optimoidaksesi sovelluksesi.
Kaggle-haaste kestää noin kolme kuukautta. Kolmen kuukauden ajan sinun tulee keskittyä koneoppimistuloksen optimointiin. Haluat olla suuri haitta, jos päätät osallistua haasteeseen keston puolivälissä. Muut osallistujat haluavat aina olla askeleen edellä.
Älä keskity itsesi liikaa yhteen malliratkaisuun. Jos yrität useita ratkaisuja, voit päättää parhaan vaihtoehdon tai laittaa useita tekniikoita yhteen. Keskityn osallistumiseni aikana vain yhteen ratkaisuun ja yritin optimoida sen. Jälkeenpäin mielestäni olisi parempi kokeilla muita strategioita ja tekniikoita.
Kommunikoi muiden Kaggle-osallistujien kanssa tai osallistu ryhmään jakamaan ideoita. Uusien ideoiden lisäksi toinen etu olisi enemmän laskentakapasiteettia. Voit jakaa testitiedot ja toimittaa tulokset nopeammin.
johtopäätös
Kuten huomaat, keksin ensimmäisessä Kaggle Challenge -palvelussa paljon uutta. Toivon, että hyväksyt nämä ehdotukset myös haasteessasi. Kaggle-haasteilla on huomattava etu oppia koneoppimisen aihe ja saada vähän taloudellista tukea, jos teet sen hyvin.
Yleiskatsaus koodini on täällä. Jos sinulla on kysyttävää, haluaisin kuulla sinusta. Muutoin voin toivottaa sinulle vain hauskaa seuraavassa Kaggle Challengessasi!
Viitteet
"Suuren mittakaavan kuvanhaku tarkkaan syvällä paikallisella ominaisuudella", Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, Bohyung Han, Proc. ICCV’17
Related Posts
-

Vanhempien kuuleminen – antroposofinen kasvatusneuvoja
Vanhempien kuulemisaika – antroposofinen kasvatusneuvoja Opetusopas: Vanhempien neuvonta Vanhempien kuulemisaika on 450 sivua, ja siinä on todellinen…
-
Diatsepaami ⚕ -vaikutus, sivuvaikutukset, annostus
Ymmärrä pelko Diatsepaami yhdellä silmäyksellä diatsepaamia kuuluu ns. bentsodiatsepiinien lääkeryhmään, jota kielellisesti kutsutaan…
-

Koulutusneuvonta – avun saaminen on merkki osaamisesta
Koulutusneuvonta – Koulutuksen ongelmat eivät ole enää tabu Jos vanhemmat eivät esimerkiksi pääse lasten kasvatuksessa eteenpäin, jos esimerkiksi syntyy…
-

Sydämen pysähtymisen syyt ja oireet – naturopatia – naturopaattien asiantuntijaportaali
Sydämen pysähtymisen syyt ja oireet Tämä teksti on lääketieteellisen kirjallisuuden, lääketieteellisten ohjeiden ja nykyisten tutkimusten mukainen, ja…